

Way back when, with the advances of computational linguistics in the 70s and 80s, some people thought that machine translation would be a solvable problem within years. That you could even travel the world with a portable computer, only the size of a backpack, that would simultaneously translate any spoken utterance to any other language. Over the years, there were a lot of research projects like PaPeRo, ATR-MATRIX, or Verbmobil to achieve this goal. Nowadays, with the Google Translate App on Android and iOS, you can easily do this with any mobile device – as long as you have an Internet connection.
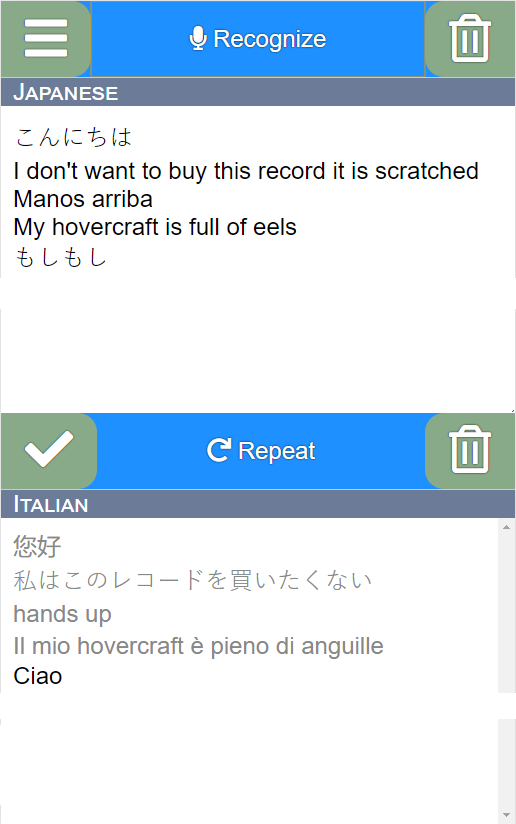
But is this also possible with a pure web page using only HTML, CSS, and Javascript? We’d need speech recognition, machine translation and speech synthesis as Javascript APIs or web services,
Web-based speech recognition is only available with Chrome or Chrome-based browsers, like Microsoft Edge Beta on Desktop or Samsung Internet on Android. On Android, Opera and Microsoft Edge also offer a working speech recognition function. With Firefox and Safari, you’re out of luck here. Firefox started to implement the Web Speech API in 2015, but as of 2019, there is yet no full working solution implemented for speech recognition, comparable to the implementation offered by Chrome-based browsers.
Machine translation can be achieved by using the Google Translate API. This is a cloud service you can use after registration which is (effectively) free for the first 500.000 characters.
Speech synthesis is available with more browsers, though your mileage may vary. Chrome-based browsers also offer the most available voices, though the mobile version is restricted. Desktop browsers like Firefox and Microsoft Edge only support languages that are locally installed. MacOS Safari seems to work, but obviously has severe problems with pronouncing non-latin characters.
The following table contains an overview of the state of the Web Speech API implementation for some browsers:
| OS / Browser | Recognition | Synthesis |
|---|---|---|
| Windows | ||
| Chrome | ✔ | ✔ |
| Firefox | ✗ | ✔ (only locally installed voices) |
| Edge | ✗ | ✔ (only locally installed voices) |
| Edge Beta | ✔ | ✔ |
| Internet Explorer | ✗ | ✗ |
| macOS | ||
| Safari | ✗ | ✔ (problems with pronouncing non-latin characters) |
| Chrome | ✔ | ✔ |
| Firefox | ✗ | ✔ |
| Debian Linux | ||
| Chrome | ✔ | ✔ |
| Firefox | ✗ | ✔ |
| Android | ||
| Chrome | ✔ | ✔ (reduced number of voices compared to desktop) |
| Samsung Internet | ✔ | ✔ |
| Edge | ✔ | ✔ |
| Firefox | ✗ | ? (no voices found) |
| Opera | ✔ | ? (no voices found) |
| iOS | ||
| Safari | ✗ | ✔ (shaky implementation: sometimes no voices found or no sound) |
| Others | like Safari |
You can test all of this by clicking on this button which opens the application in a new tab. On a mobile device, you can also install it as a Progressive Web App to the home screen.
But as this is a software developer’s blog, we are obviously not finished yet.
Implementing Speech Recognition
The speech recongition API can be accessed using the
webkitSpeechRecognition
(Chrome) or the
SpeechRecognition
(Firefox) object:
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.maxAlternatives = 1;
recognition.lang = "en-US";
recognition.start();
For security reasons, speech recognition can only be started in an event handler triggered by a user gesture (like click or touch). The recognition process then fires a sequence of events, where the most important are
onresult
,
onerror
,
onnomatch
,
onstart
, and
onend
. We gather the recognition result by implementing an
onresult
handler:
recognition.onresult = function(event)
There seems to be a bug in the mobile implementation where the flag
isFinal
is always set to true. In our demo application, there is a workaround for that: the recognition result is considered final when there is no new changed result for a certain period of time.
Implementing Translation
There is no Web standard for translating languages, yet there are quite a number of cloud-based services to do the job. e.g. DeepL, Google Translate, Yandex, IBM Watson, and Microsoft Translator, just to name a few. In this demo application, Google Translate is used for convenience, offering a generous free quota per month. The service can be accessed with a simple HTML request, obtaining the result as a JSON formatted data packet.
var url = "https://translation.googleapis.com/language/translate/v2";
url += "?key=" + apiKey;
url += "&q=" + encodeURIComponent(text);
url += "&target=" + targetLanguage;
var req = new XMLHttpRequest();
req.open("GET", url, true);
req.onload = function()
To use Google Translate, you have to register for an API key. This demo uses a simple proxy to hide the API key used while also caching the requests to reduce the load. Even though the free tier offered by Google Translate is generous, it is not unlimited. So all requests are limited to a number of hundred requests per day and IP address. If this is not enough, you can register and obtain your own API key and enter it in the configuration menu of the demo application.
Implementing Speech Synthesis
For speech synthesis, we obtain a reference to the
speechSynthesis
object and call the
getVoices()
function. Using Chrome, the list of available voices is populated asynchronously using the
onvoiceschanged
event, whereas, in Firefox and other browsers, we can just call this function directly.
var voices;
if (speechSynthesis.onvoiceschanged !== undefined)
var synthesizer = window.speechSynthesis;
voices = synthesizer.getVoices();
To trigger speech output, we create an instance of the
SpeechSynthesisUtterance
object, set all necessary parameters, including the language of one of the possible voices obtained and call the
speak()
function of the
speechSynthesis
object:
var utterance = new SpeechSynthesisUtterance();
utterance.pitch = 1;
utterance.rate = 1;
utterance.volume = 1;
utterance.text = text;
utterance.lang = "en-US";
synthesizer.speak(utterance);
Where to go from here
A history of machine translation from the Cold War to deep learning
Google Translate App for Android and iOS
Machine translation Web services: Google Translate, DeepL, Yandex, IBM Watson Language Translator, Microsoft Translator Text API